[infobox title="①.安装包下载并解压"]
官方下载地址:https://www.mongodb.com/download-center/community
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.6.tgztar -zxvf mongodb-linux-x86_64-rhel70-4.2.6.tgz -C /export/server/[/infobox]
[infobox title="②.环境变量配置"]
vim /etc/profile.d/mongodb.sh在profile.d下创建mongodb.sh文件,环境变量配置
MONGODB_HOME=/export/server/mongodb-linux-x86_64-rhel70-4.2.6
PATH=$PATH:$MONGODB_HOME/bin使/etc/profile里的配置立即生效 [kbd]source /etc/profile[/kbd]
[/infobox]
[infobox title="相关文件配置"]
创建data及logs目录 ,mongo.log文件
mkdir $MONGODB_HOME/logs $MONGODB_HOME/data
touch $MONGODB_HOME/logs/mongo.log
chmod 777 data/ logs/
创建mongodb.conf文件 [kbd]vim $MONGODB_HOME/mongodb.conf[/kbd]
port=27017
dbpath= /export/server/mongodb-linux-x86_64-rhel70-4.2.6/data #数据库存文件存放目录
logpath= /export/server/mongodb-linux-x86_64-rhel70-4.2.6/logs/mongo.log #日志文件存放路径
logappend=true #使用追加的方式写日志
fork=true #后台运行,以守护进程的方式运行,创建服务器进程
maxConns=100 #最大同时连接数
noauth=true #不启用验证
journal=true #每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。
#即使宕机,启动时wiredtiger会先将数据恢复到最近一次的checkpoint点,然后重放后续的journal日志来恢复。
storageEngine=wiredTiger #存储引擎有mmapv1、wiretiger、mongorocks
bind_ip = 0.0.0.0 #允许任何IP进行连接
[/infobox]
[infobox title="使用配置文件启动服务"]
mongod -f mongodb.conf通过bin/mongo或Robo 3T进行访问
[/infobox]
[infobox title="MongoDB关闭"]
mongod 命令关闭
mongod --shutdown --dbpath /export/server/mongodb-linux-x86_64-rhel70-4.2.6/data/MongoDB shell命令关闭
use admin;
db.shutdownServer();[/infobox]
[infobox title="MongoDB介绍"]
[successbox title="背景"]
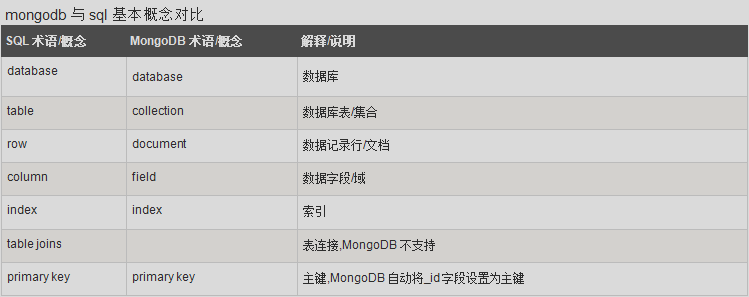
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。它是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
其放弃关系模型的原因就是为了获得更加方便的扩展、稳定容错等特性。面向文档的基本思路就是:将关系模型中的“行”的概念换成“文档(document)”模型。面向文档的模型可以将文档和数组内嵌到文档中。因此,实际中可以用一条数据表示非常复杂的结构。MongoDB没有预定义模式:文档的键(key)和值(value)不再是固定的类型和大小,而且根据需求要添加或者删除字段变得更容易了。
实际应用中,随着数据量的增大,数据库都要进行扩展。扩展有纵向扩展和横向扩展。纵向扩展是使用计算能力更强的机器,也是最省力的方法,但是很容易达到物理极限,无论花多少钱也买不到最新的机器了。横向扩展就是通过分区将数据分散到更多的机器上。MongoDB的设计采用横向扩展。面向文档的数据模型使它很容易地在多台服务器之间进行数据分割。还可以自动处理跨集群的数据和负载,自动重新分配文档,以及将用户请求路由到正确的机器上。开发者根本不用考虑数据库层次的扩展问题,需要扩展数据库时,在集群中添加机器即可,MongoDB会自动处理后续的事情。

[/successbox]
[successbox title="MongoDB的优势与劣势"]
优势
-
- 快速!基于内存,将热数据存放在物理内存中(不仅仅只是索引和少部分数据),从而提高了整体速度和效率。
- 高扩展性!MongoDB的高可用和集群架构拥有十分高的扩展性。
- 自身的FailOver机制!在副本集中,当主库遇到问题,无法继续提供服务的时候,副本集将选举一个新的主库继续提供服务。
- JSon格式的数据!MongoDB的Bson和JSon格式的数据十分适合文档格式的存储与查询。
劣势
-
- 应用经验少!由于NoSQL兴起时间短,应用经验相比关系型数据库较少。
- 由于以往用到的都是关系型数据库,可能会造成使用者一开始的不适应。
- 无事务机制!MongoDB本身没有自带事务机制,若需要在MongoDB中实现事务机制,需通过一个额外的表,从逻辑上自行实现事务。
[/successbox]
[successbox title="MongoDB数据类型"]

[/successbox]
[successbox title="MongoDB语法与现有关系型数据库SQL语法比较"]

https://www.cnblogs.com/java-spring/p/9488200.html
[/successbox]
[/infobox]
[successbox title="常用命令"]

01 db:查看当前的数据库;
02 show dbs:显示所有数据库列表;
03 db.stats():查看数据库状态;
04 use:切换或创建数据库;
05 db.dropDatabase():删除数据库(需要先切换到对应的数据库);(用的时候自己创建)
06 db.createCollection(name, options):创建集合;(用的时候自己创建)
07 db.${collection}.drop():删除集合;
08 db.${collection}.insert():插入文档;
09 db.${collection}.save():插入文档;
10 db.${collection}.findOne():查看一篇文档;
11 db.${collection}.find().pretty():以更加友好的方式查看已插入文档;
12 db.collection.update():更新文档;
13 db.collection.remove():删除文档;但是并不会释放存储空间,需执行db.repairDatabase() 来回收磁盘空间。推荐deleteOne(),deleteMany();
14 db.${collection}.deleteMany({}):删除全部文档
15 db.${collection}.deleteOne({}):删除符合条件的一个文档
16 db.${collection}.find().limit(${num}):读取指定数量的数据记录;
17 db.${collection}.find().limit(${num1}).skip(${num2}):跳过指定数量的数据
18 db.${collection}.find().sort({${key}:1/-1}):排序,1升序,-1降序
19 db.${collection}.createIndex():创建索引
20 db. ${collection}.help(); #查询对相应表的一些操作
21 db.mycoll.find().help(); #查询的方法,排序,最大最小等...
[infobox title="插入"]
mongoDB中插入数据有insert()与save()两个命令,二者的联系是:
1 对于数据库中没有改字段,两者没有区别;
2 对于数据库中有该字段,insert会报错,save会执行更新操作
3 若新增的数据中存在主键 ,insert() 会提示错误,而save() 则更改原来的内容为新内容。
save()
db.student.save({_id:1,classid:1,age:18,name:"little1",love:["football","swing","cmpgame"]});
db.student.save({_id:2,classid:2,age:19,name:"little2",love:["play"]});
db.student.save({_id:3,classid:2,age:20,name:"little3"});
db.student.save({_id:4,classid:1,age:21,name:"little4"});
db.student.save({_id:5,classid:1,age:22,name:"little5",opt:"woshisheia"});
db.student.save({_id:6,classid:2,age:23,name:"23little4"});
insert():int类型赋值不要加引号,字符串赋值要加引号,单引号和双引号都可以,推荐使用单引号,因为双引号在一些编辑器中转义会有一些问题
1 插入普通数据命令: db.goods.insert({name:'xiaomi',price:2000,number:'50'})
2 插入具有对象数据命令:db.goods.insert({name:'xiaomi',price:2000,number:'50',area:{province:'jiangsu',city:'nanjing'}})
3 插入数组数据命令: db.goods.insert({name:'xiaomi',price:2000,number:'50',area:{province:'jiangsu',city:'nanjing'},color:['black','red','greed']})
4 批量插入数据:for (i=0;i<1000;i++) db.tables1.insert({name:"Alex"+i});
[/infobox]
[infobox title="查询"]
1)find({${where条件},${0属性不显示 /1属性显示}}):查询,如果where条件没有,那就用{}表示,不能省略。而显示与否的{}可以省略的。
db.student.find();
//查询 name为little1的学生,并且只显示 age,name两个字段
db.student.find({name:"little1"},{name:1,age:1}) 等价于 select name,age from student where name = "little1"
//and:查询 name为little1,age为18的学生,并且只显示 age,name,love三个字段
db.student.find({name:"little1",age:18},{name:1,age:1,love:1}) 等价于 select name,age,love from student where name = "little1" and age = 18
//$or:查询 name为little3或age为19的学生
db.student.find({'$or':[{name:'little3'},{age:19}]}) 等价于 select * from student where name = "little3" or age = 19
db.student.find({'$or':[{name:'little3'},{age:19}]},{name,1})
2)findOne({${where条件},${0属性不显示 /1属性显示}}):查询,只返回第一个
db.student.findOne().pretty(); 这里的pretty()是将结果格式化,find() 与 findOne() 后面都可以使用
3)skip(num): 参数num表示跳过的记录条数,默认值为0。 limit(num): 参数num表示要获取文档的条数,如果没有指定参数则显示集合中的所有文档。skip() 与 limit() 不分先后顺序 ,从第二条查寻,查出三条
db.student.find().skip(1).limit(3);
4)比较运算符号
//查询出19<age<=21的数据
db.student.find({age:{$gt:19,$lte:21}});
//查询age>20的数据
db.student.find({age:{$gt:20}});
db.student.find({$where:"this.age>20"});
db.student.find("this.age>20");
var f = function(){return this.age>20};
db.student.find(f);

5)$mod:查询出age为奇数的数据(对2求余为1即为奇数)(这里请注意[2,1]的位置不能错)。
db.student.find({age:{$mod:[2,1]}}); 也可写作:
6)$exists:查询出存在opt字段的数据, 存在true,不存在false
db.student.find({opt:{$exists:true}}); db.student.find({opt:{$exists:false}});
7)查询出name不为little2的数据
db.student.find({name:{$ne:"little2"}});
8)$in:查询出age为16,18,19的数据
db.student.find({age:{$in:[16,18,19]}});
9)$nin:查询出age不为16,18,19的数据
db.student.find({age:{$nin:[16,18,19]}});
10)$size:查询出love有三个的数据
db.student.find({love:{$size:3}});
11)查询出name不是以litt开头的数据
db.student.find({name:{$not:/^litt.*/}});
12)sort:1升序, -1降序
按age升序:db.student.find().sort({age:1}); 按age降序:db.student.find().sort({age:-1});
13)count:查询数据条数。db.集合名称.find({条件}).count() 或者 db.集合名称.count({条件})
db.student.find().count(); 也可以写作db.student.count()
14)like:模糊查询
db.student.find({name:/little/}); 相当于 select * from student where name like "%little%";
db.student.find({name:/^little/}); 相当于 select * from users where name like "little%";
15)distinct:去重。格式:db.集合名称.distinct('去重字段',{条件})
db.student.distinct('name');
//查找年龄大于18的学生,来自哪些省份
db.stu.distinct('hometown',{age:{$gt:18}})
16)type:属性类型判断 常见的Double 是1,String是2,Boolean是8,Date是9,Null是10,32位int是16,Timestamp是17,64位int是18
db.sutdent.find({"title" : {$type : 2}}) db.student.find({"title" : {$type : 'string'}})
17)null:查询age为null的数据
db.student.find({age:null})
18)聚合(aggregate),主要用于计算数据,类似sql中的sum()、avg()
[/infobox]
[infobox title="更新"]
update() 方法用于更新已存在的文档。语法格式如下
db.collection.update(
<query>,
<update>,
{
upsert: ,
multi: ,
writeConcern:
}
)参数说明:
-
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
例:
db.person.insert([{"name":"chen","age":15},{"name":"li","age":20},{"name":"zhang","age":20}]);
$ set修改符
用于修改键的值,如果键不存在就增加键
//将age=10的数据改成15,默认如果age=10的有多条记录只更新第一条
db.person.update({"name":"li"},{$set:{"age":10}})
//更新多个满足条件的值,同时如果更新的值不存在就插入更新的值,注意:这里插入的值是20不是30
db.person.update({"age":30},{$set:{"age":20}},{multi:true,upsert:true})
可以省略multi,upsert,这里不能有花括号,但是不建议这样做
db.person.update({"age":30},{$set:{"age":20}},true,true)
//值更新为数组
db.person.update({"name":"zhang"},{$set:{"age":[10,12,14]}},{upsert:true})
//修改为其它的值
db.person.update({"name":"zhang"},{$set:{"age":''}},{upsert:true})
db.person.update({"name":"zhang"},{$set:{"age":null}},{upsert:true})
$inc修改符
用于增加已有键的值,如果键不存在就创建,只能用于整形、长整型、浮点型。
//将name=zhang的记录的age键+10
db.person.update({"name":"zhang"},{$inc:{"age":10}},{upsert:true})
//将name=zhang的记录的age键-10
db.person.update({"name":"zhang"},{$inc:{"age":-10}},{upsert:true})
$unset修改符
删除键类似关系数据库的删除字段操作,要区别$set修改符的将键设空或者null值
db.person.update({"name":"zhang"},{$unset:{"age":1}})
[/infobox]
[infobox title="索引"]
从mongoDB 3.0开始ensureIndex被废弃,使用 createIndex创建索引。创建索引,需要传递两个参数 ①:建立索引的字段名称,②排序参数 1升序,-1降序。
1)建立单索引。
db.student.createIndex({name:1}) 表示给name字段建立索引,按照升序的排序
2)建立复合索引。
db.student.ensureIndex({name:1,age:-1}) 建立一个复合索引,表示给name和age都建立索引,按照name的升序,和age的降序
[/infobox]


https://www.cnblogs.com/java-spring/p/9488200.html
https://www.cnblogs.com/java-spring/p/9488227.html
[/successbox]
[infobox title="code"]
通过GridFS从Mongodb读取文件
public static void main(String[] args) throws IOException {
MongoClient mongoClient = new MongoClient("192.168.199.181", 27017);
GridFS gridFS = new GridFS(mongoClient.getDB("test"));
// 读取文件
GridFSDBFile outFile = gridFS.findOne("test.jpg");
outFile.writeTo(new File("C:\\Users\\kami\\Desktop\\aaa.png"));
mongoClient.close();
}
public void downFile(HttpServletResponse response){
String fileId = "5c0f7c374fc404123403d69e";//这里可以通过参数取代
try {
MongoClient client = new MongoClient("192.168.199.181",27017);
DB db = client.getDB("test.jpg");
GridFS fs = new GridFS(db);
GridFSDBFile gridFSDBFile = fs.findOne(new ObjectId(fileId));
OutputStream sos = response.getOutputStream();
response.setContentType("application/octet-stream");
// 获取原文件名
String name = (String) gridFSDBFile.get("filename");
String fileName = new String(name.getBytes("GBK"), "ISO8859-1");
// 设置下载文件名
response.addHeader("Content-Disposition", "attachment; filename=\"" + fileName + "\"");
// 向客户端输出文件
gridFSDBFile.writeTo(sos);
sos.flush();
sos.close();
} catch (IOException e) {
e.printStackTrace();
}
}通过GridFS往Mongodb上传文件
MongoClient mongoClient = new MongoClient("192.168.199.181", 27017);
// 存储文件信息
GridFS gridFS = new GridFS(mongoClient.getDB("test"));
File localFile = new File("D:\\236318-106.jpg");
GridFSInputFile oneFile = gridFS.createFile(localFile);
oneFile.setFilename("test.jpg");
//配置文件属性
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//设置日期格式
BasicDBObject metadata = new BasicDBObject();
metadata.put("uploadDate", df.format(new Date()));
oneFile.setMetaData(metadata); //添加属性
oneFile.save(); //保存文件Mongodb集合中查询所有
MongoClient mongoClient = new MongoClient("192.168.199.181", 27017);
MongoDatabase mongoClientDatabase = mongoClient.getDatabase("test");
MongoCollection collection = mongoClientDatabase.getCollection("rua");
FindIterable documents = collection.find();
for (Document document : documents) {
System.out.println(document);
}
mongoClient.close();通过sparkSql查询数据
val spark = SparkSession.builder()
.master("local[*]")
.appName("rua")
.config("spark.mongodb.input.uri", "mongodb://192.168.199.181/test.root")
.getOrCreate()
// 设置log级别
spark.sparkContext.setLogLevel("WARN")
val df = MongoSpark.load(spark)
df.show()
df.createOrReplaceTempView("test")
val resDf = spark.sql("select * from test")
resDf.show()
// spark.sql("select * from test where name REGEXP '^Jack1'").show()
spark.stop()
System.exit(0)[/infobox]
Comments NOTHING