[infobox title="集群规划"]
| 节点名称 | IP | Zookeeper | Master | Worker |
| node21 | 192.168.100.21 |
Zookeeper |
主Master | Worker |
| node22 | 192.168.100.22 |
Zookeeper |
备Master | Worker |
| node23 | 192.168.100.23 |
Zookeeper |
Worker |
[/infobox]
[infobox title="前置需求"]
-
- Java8 安装成功
- zookeeper 安装参考:Apache ZooKeeper 集群搭建
- hadoop 安装参考:Centos7下Apache Hadoop 3.2.1伪分布式部署安装 已更换为分布式安装
- Scala
[/infobox]
[infobox title="Scala安装"]
https://www.scala-lang.org/download/
下载 wget https://downloads.lightbend.com/scala/2.13.2/scala-2.13.2.tgz
解压 tar -zxvf scala-2.13.2.tgz -C /export/server/
配置环境变量
vim /etc/profile.d/scala.shexport SCALA_HOME=/export/server/scala-2.13.2
export PATH=$PATH:$SCALA_HOME/binsource /etc/profile若修改错误 可通过expro重新修改环境变量
export PATH=/bin:/usr/bin:$PATH通过scp分发至其他节点进行相应步骤
[/infobox]
[infobox title="Zookeeper安装"]
http://mirror.bit.edu.cn/apache/zookeeper/
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.gz
tar -zxvf apache-zookeeper-3.6.1-bin.tar.gz -C /export/server/
cd /export/server/apache-zookeeper-3.6.1-bin/conf
cp zoo_sample.cfg zoo.cfg vim zoo.cfg
修改内容: dataDir=/export/server/apache-zookeeper-3.6.1-bin/zkdata
添加内容: # (心跳端口、选举端口)
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
记得不要带空格环境变量配置
vim /etc/profile.d/zookeeper.sh
export ZOOKEEPER_HOME=/export/server/apache-zookeeper-3.6.1-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profilesource /etc/profile
通过scp分发至其他节点并进行相应动作
在zkdata中touch myid
写入server对应的编号:如 1
查看日志 zkServer.sh start-foreground
[warningbox title="管理脚本"]
#! /bin/bash
case $1 in
"start"){
for i in node01 node02 node03
do
ssh $i "/export/server/apache-zookeeper-3.6.1-bin/bin/zkServer.sh start"
done
};;
"status"){
for i in node01 node02 node03
do
ssh $i "/export/server/apache-zookeeper-3.6.1-bin/bin/zkServer.sh status"
done
};;
"stop"){
for i in node01 node02 node03
do
ssh $i "/export/server/apache-zookeeper-3.6.1-bin/bin/zkServer.sh stop"
done
};;
esac[/warningbox]
[/infobox]
[infobox title="Spark安装"]
http://spark.apache.org/downloads.html
wget https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /export/server/
cp spark-env.sh.template spark-env.sh
vim修改,末尾追加
#指定默认master的ip或主机名
export SPARK_MASTER_HOST=node01
#指定maaster提交任务的默认端口为7077
export SPARK_MASTER_PORT=7077
#指定masster节点的webui端口
export SPARK_MASTER_WEBUI_PORT=8080
#每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=1g
#允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心)
export SPARK_WORKER_CORES=3
#每个worker从节点的实例(可选配置)
export SPARK_WORKER_INSTANCES=1
#指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项
export HADOOP_CONF_DIR=/export/server/hadoop-3.2.1/etc/hadoop/
#指定整个集群状态是通过zookeeper来维护的,包括集群恢复
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181
-Dspark.deploy.zookeeper.dir=/spark"
cp slaves.template slaves
vim slaves
末尾修改
node01
node02
node03
环境变量配置
vim /etc/profile.d/spark.sh
export SPARK_HOME=/export/server/spark-2.4.5-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
scp分发,修改node02节点上spark-env.sh配置的MasterIP为SPARK_MASTER_IP=node02
集群启动sbin/start-all.sh
备用master节点需要手动启动sbin/start-master.sh
[/infobox]
[warningbox title="配置历史服务器"]
1 临时配置
对本次提交的应用程序起作用
./spark-shell --master spark://node21:7077 --name myapp1 --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://node21:8020/spark/test
停止程序,在Web Ui中Completed Applications对应的ApplicationID中能查看history。
2 永久配置
spark-default.conf配置文件中配置HistoryServer,对所有提交的Application都起作用
在客户端节点,进入../spark-2.3.1/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能
spark.eventLog.enabled true
//设置事件日志存储的目录
spark.eventLog.dir hdfs://node21:8020/spark/test
//设置HistoryServer加载事件日志的位置
spark.history.fs.logDirectory hdfs://node21:8020/spark/test
//日志优化选项,压缩日志
spark.eventLog.compress true启动HistoryServer:
./start-history-server.sh
访问HistoryServer:node21:18080,之后所有提交的应用程序运行状况都会被记录。
[/warningbox]
[infobox title="集群提交命令方式"]
1 Standalone模式
1.1 Standalone-client
(1)提交命令
[admin@node21 spark-2.3.1]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master spark://node21:7077 \ --executor-memory 500m \ --total-executor-cores 1 \ examples/jars/spark-examples_2.11-2.3.1.jar 10
或者
[admin@node21 spark-2.3.1]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master spark://node21:7077 \ --deploy-mode client \ --executor-memory 500m \ --total-executor-cores 1 \ examples/jars/spark-examples_2.11-2.3.1.jar 10
(2)提交原理图解
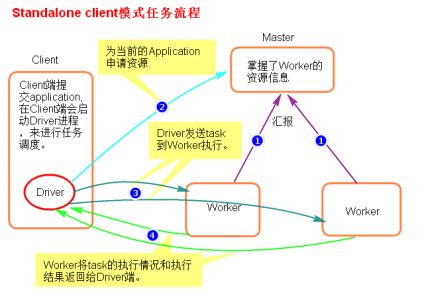
(3)执行流程
- client模式提交任务后,会在客户端启动Driver进程。
- Driver会向Master申请启动Application启动的资源。
- 资源申请成功,Driver端将task发送到worker端执行。
- worker将task执行结果返回到Driver端。
(4)总结
client模式适用于测试调试程序。Driver进程是在客户端启动的,这里的客户端就是指提交应用程序的当前节点。在Driver端可以看到task执行的情况。生产环境下不能使用client模式,是因为:假设要提交100个application到集群运行,Driver每次都会在client端启动,那么就会导致客户端100次网卡流量暴增的问题。
1.2 Standalone-cluster
(1)提交命令
[admin@node21 spark-2.3.1]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master spark://node21:7077 \ --deploy-mode cluster \ examples/jars/spark-examples_2.11-2.3.1.jar 10
(2)提交原理图解

(3)执行流程
- cluster模式提交应用程序后,会向Master请求启动Driver.
- Master接受请求,随机在集群一台节点启动Driver进程。
- Driver启动后为当前的应用程序申请资源。
- Driver端发送task到worker节点上执行。
- worker将执行情况和执行结果返回给Driver端。
(4)总结
Driver进程是在集群某一台Worker上启动的,在客户端是无法查看task的执行情况的。假设要提交100个application到集群运行,每次Driver会随机在集群中某一台Worker上启动,那么这100次网卡流量暴增的问题就散布在集群上。
2 Yarn模式
2.1 yarn-client
(1)提交命令
以client模式启动Spark应用程序:
$ ./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode client [options] <app jar> [app options]
例如
[admin@node21 spark-2.3.1]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ examples/jars/spark-examples_2.11-2.3.1.jar 10
(2)提交原理图解

(3)执行流程
- 客户端提交一个Application,在客户端启动一个Driver进程。
- 应用程序启动后会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
- RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
- AM启动后,会向RS请求一批container资源,用于启动Executor.
- RS会找到一批NM返回给AM,用于启动Executor。
- AM会向NM发送命令启动Executor。
- Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
(4)总结
Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
ApplicationMaster的作用:
- 为当前的Application申请资源
- 给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
2.2 yarn-cluster
(1)提交命令
以cluster模式启动Spark应用程序:
$ ./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] <app jar> [app options]
例如
[admin@node21 spark-2.3.1]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ examples/jars/spark-examples_2.11-2.3.1.jar 10
(2)提交原理图解

(3)执行流程
- 客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
- RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
- AM启动,AM发送请求到RS,请求一批container用于启动Executor。
- RS返回一批NM节点给AM。
- AM连接到NM,发送请求到NM启动Executor。
- Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
(4)总结
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
ApplicationMaster的作用:
- 为当前的Application申请资源
- 给NodeManager发送消息启动Excutor。
- 任务调度。
停止集群任务命令:yarn application -kill applicationID
[/infobox]
Comments NOTHING